Nếu bạn đang thắc mắc Google bằng cách nào có thể hiểu được nội dung trên Website của bạn. Hãy cùng NAVEE tìm hiểu khái niệm Crawling là gì?
SEO là một lĩnh vực rất rộng lớn và để hiểu hết về nó, bạn cần biết một số thuật ngữ cơ bản. Crawling là một trong những khái niệm cơ bản nhất mà bạn nên tìm hiểu khi làm SEO. Vậy Crawling là gì? Bài viết dưới đây sẽ mang đến câu trả lời chi tiết dành cho bạn.
Crawling là gì? #
Crawling (thu thập thông tin) là quá trình khám phá trong đó các công cụ tìm kiếm gửi ra một nhóm Googlebot (được gọi là trình thu thập thông tin hoặc trình thu thập dữ liệu) để tìm nội dung mới và cập nhật. Nội dung có thể khác nhau – đó có thể là trang web, hình ảnh, video, PDF,… nhưng bất kể định dạng nào, nội dung hầu hết được phát hiện bởi các liên kết.
Googlebot bắt đầu bằng cách tìm nạp một vài trang Web và sau đó theo các liên kết trên các trang Web đó để tìm URL mới. Bằng cách này, trình thu thập thông tin có thể tìm thấy nội dung mới và thêm nó vào chỉ mục của họ có tên là Caffeine. Đây được biết đến là một cơ sở dữ liệu lớn về các URL được phát hiện thông qua các liên kết và được tìm kiếm bởi người dùng.

Làm thế nào để tối ưu quá trình công cụ tìm kiếm Crawling trang Web của bạn? #
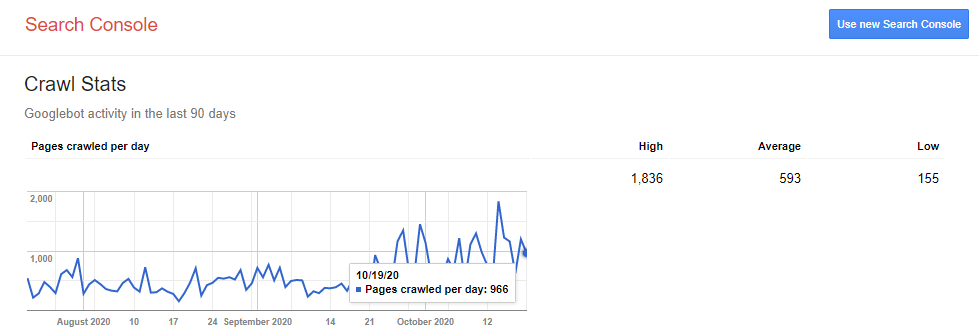
Để tối ưu quá trình Crawling, trước tiên cần kiểm tra đồ thị Crawling của Google ra sao.
Nhấn vào dòng “Please select a property” để xem được chỉ số Crawling của trang Web.

Từ đây, có thể nhận định được tần suất Crawling của Google đối với Website của bạn. Qua đó, giúp đưa ra những giải pháp phù hợp để cải thiện vấn đề này.
Cụ thể, có thể liệt kê một số phương pháp giúp Google tăng tần suất Crawling các trang nội dung trong Website:
- Cập nhật nội dung mới, chất lượng thường xuyên.
- Tối ưu tốc độ tải trang.
- Đính kèm thêm file Sitemap.xml.
- Cải thiện tốc độ phản hồi từ Server dưới 200ms, theo Google.
- Xóa bỏ những nội dung trùng lặp trên Website.
- Chặn Googlebot quét những trang không cần thiết trong file Robots.txt.
- Tối ưu hình ảnh và video (nếu có).
- Tối ưu cấu trúc link nội bộ, sử dụng những Backlink chất lượng đổ về.
Cách để ngăn Google Crawling những dữ liệu không quan trọng trên Website #
Hầu hết mọi người nghĩ về việc đảm bảo Google có thể tìm thấy các trang quan trọng của họ. Nhưng lại quên mất rằng có những trang bạn không muốn Googlebot tìm thấy.
Những trang này có thể bao gồm những thứ như:
- URL cũ có nội dung mỏng.
- URL trùng lặp (chẳng hạn như tham số sắp xếp và bộ lọc cho thương mại điện tử).
- Trang mã quảng cáo đặc biệt.
- Trang dàn dựng hoặc thử nghiệm.
Dưới đây là một số cách giúp bạn ngăn Google Crawling dữ liệu không quan trọng Website của bạn.
Sử dụng Robots.txt #
Để hướng Googlebot ra khỏi các trang và phần nhất định trên trang web của bạn, hãy sử dụng Robots.txt.
Robots.txt là gì? #
Các tệp Robots.txt được đặt trong thư mục gốc của các trang web (ví dụ: yourdomain.com/robots.txt). Tệp này giúp đề xuất phần nào trong công cụ tìm kiếm trang web của bạn nên và không nên thu thập dữ liệu, cũng như tốc độ chúng thu thập dữ liệu trang web của bạn , thông qua các chỉ thị cụ thể trên file Robots.txt.
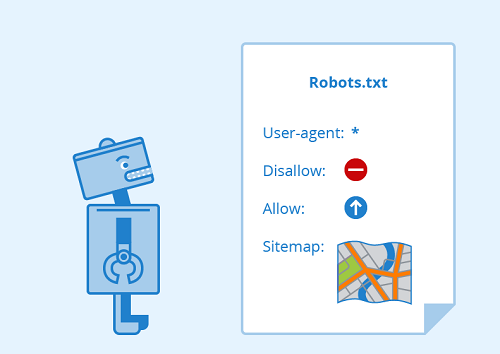
Cách Googlebot xử lý tệp Robots.txt #
- Nếu Googlebot không thể tìm thấy tệp Robots.txt cho một trang web, nó sẽ tiến hành thu thập dữ liệu trang web.
- Nếu Googlebot tìm thấy tệp Robots.txt cho một trang web, nó thường sẽ tuân theo các đề xuất và tiến hành thu thập dữ liệu trang web.
- Nếu Googlebot gặp lỗi trong khi cố gắng truy cập tệp Robots.txt của trang web và không thể xác định xem có tồn tại hay không, nó sẽ không thu thập dữ liệu trang web.
Tối ưu hóa cho ngân sách thu thập #
Ngân sách thu thập (Crawl Budget) ở đây là số lượng URL trung bình Googlebot sẽ thu thập dữ liệu trên trang web của bạn trước khi rời khỏi.
Vì vậy, để tối ưu hóa quá trình Crawling, hãy đảm bảo rằng:
- Googlebot không quét các trang không quan trọng và có nguy cơ bỏ qua các trang quan trọng của bạn.
- Chặn trình thu thập thông tin truy cập nội dung mà bạn chắc chắn không quan trọng.
- Không chặn quyền truy cập của trình thu thập thông tin vào các trang bạn đã thêm các chỉ thị khác, chẳng hạn như thẻ “Canonical” hoặc “Noindex”.
Cần lưu ý rằng, nếu Googlebot bị chặn từ một trang, nó sẽ không thể xem hướng dẫn trên trang liên kết khác.
Tuy nhiên, không phải tất cả các Robot Web đều tuân theo chỉ thị trong file Robots.txt. Trên thực tế, việc đặt vị trí của các URL đó trong tệp Robots.txt có thể công khai những nội dung riêng tư của Website. Điều đó cũng có nghĩa là những người có ý định xấu có thể dễ dàng tìm thấy chúng hơn.
Thế nên, tốt hơn hết là “Noindex” các trang này và đặt chúng sau một biểu mẫu đăng nhập thay vì vào tệp Robots.txt của bạn.
Xác định tham số URL trong Google Search Console #
Một số Website (phổ biến nhất với thương mại điện tử) cung cấp cùng một nội dung trên nhiều URL khác nhau bằng cách nối thêm các tham số nhất định vào URL. Điển hình là sử dụng các bộ lọc.
Ví dụ: bạn có thể tìm kiếm những giày thể thao trên Shopee, sau đó tinh chỉnh tìm kiếm của bạn kiểu dáng, nơi cung ứng… Mỗi lần bạn tinh chỉnh, URL sẽ thay đổi một chút:

Làm cách nào Google biết phiên bản URL nào sẽ phục vụ cho người tìm kiếm?
Google thực hiện công việc khá tốt khi tự mình tìm ra URL chính. Nhưng bạn có thể sử dụng tính năng Thông số URL trong Google Search Console để cho Google biết chính xác cách bạn muốn họ đối xử với các trang của mình.
Nếu bạn sử dụng tính năng này để báo cho Googlebot, thu thập dữ liệu không có URL nào có tham số, thì về cơ bản, bạn đang yêu cầu ẩn nội dung này khỏi Googlebot. Điều này có thể dẫn đến việc xóa các trang đó khỏi kết quả tìm kiếm. Đó là những gì bạn muốn nếu các tham số đó tạo các trang trùng lặp, nhưng không lý tưởng nếu bạn muốn các trang đó được lập chỉ mục.
Cách để Google Crawling tất cả nội dung quan trọng của bạn #
Bây giờ bạn đã biết một số chiến thuật để đảm bảo trình thu thập công cụ tìm kiếm tránh xa nội dung không quan trọng của bạn. Hãy tìm hiểu về cách tối ưu hóa có thể giúp Googlebot tìm thấy các trang quan trọng của bạn.
Đôi khi một công cụ tìm kiếm sẽ có thể tìm thấy các phần của trang web của bạn bằng cách thu thập thông tin. Nhưng các trang hoặc phần khác có thể bị che khuất vì lý do này hay lý do khác. Điều quan trọng là đảm bảo rằng các công cụ tìm kiếm có thể khám phá tất cả nội dung bạn muốn lập chỉ mục và không chỉ trang chủ của bạn.
Hãy tự hỏi mình điều này: Googlebot có thể Crawl trang Web của bạn không?
Nếu bạn yêu cầu người dùng đăng nhập, điền vào biểu mẫu hoặc trả lời khảo sát trước khi truy cập một số nội dung nhất định, các công cụ tìm kiếm sẽ không thấy các trang được bảo vệ đó. Một trình thu thập thông tin chắc chắn sẽ không đăng nhập.
Bạn có đang dựa vào các hình thức tìm kiếm? #
Googlebot sẽ gặp khó khăn khi quét dữ liệu vì các hình thức tìm kiếm. Một số cá nhân tin rằng nếu họ đặt Search Box trên trang Web của họ, công cụ tìm kiếm sẽ có thể tìm thấy mọi thứ mà khách truy cập của họ tìm kiếm. Tuy nhiên điều này có thể ngăn việc Googlebot thu thập dữ liệu trên trang Web. Vì vậy hãy cân nhắc kỹ lưỡng trọng việc cài đặt Search Box trong Website.
Hidden Text truyền tải nội dung qua phi văn bản #
Không nên sử dụng các hình thức đa phương tiện (hình ảnh, video, GIF,…) để hiển thị văn bản mà bạn muốn được lập chỉ mục. Mặc dù các công cụ tìm kiếm đang trở nên tốt hơn trong việc nhận dạng hình ảnh, nhưng không có gì đảm bảo họ sẽ có thể đọc và hiểu nó. Thế nên, tốt nhất là thêm văn bản trong phần đánh dấu <HTML> của trang Web của bạn.
Công cụ tìm kiếm có thể theo dõi điều hướng trang web của bạn? #
Googlebot khám phá trang Web thông qua các Backlink từ các trang Web khác trỏ về hoặc hệ thống Internal Link của các trang trên tổng thể Website.
Nếu bạn đã có một trang mà bạn muốn các công cụ tìm kiếm tìm thấy nhưng nó không được liên kết đến từ bất kỳ trang nào khác, thì nó gần như vô hình. Ngoài ra, một số Website mắc sai lầm nghiêm trọng trong việc cấu trúc điều hướng của họ theo những cách không thể tiếp cận với các công cụ tìm kiếm. Điều đó làm cản trở khả năng được liệt kê trong kết quả tìm kiếm.
Các lỗi điều hướng phổ biến khiến Googlebot không nhìn thấy trang Web của bạn #
Đây là lý do tại sao trang web của bạn có điều hướng nên rõ ràng và cấu trúc thư mục URL hữu ích:
- Không đồng nhất điều hướng trên Mobile và điều hướng trên Desktop.
- Bất kỳ loại điều hướng nào trong đó các mục menu không có trong HTML, chẳng hạn như điều hướng hỗ trợ JavaScript. Google đã thu thập thông tin tốt hơn và hiểu Javascript, nhưng đây vẫn chưa phải là một quy trình hoàn hảo. Cách chắc chắn hơn để đảm bảo một cái gì đó được tìm thấy, hiểu và lập chỉ mục bởi Google là bằng cách đưa nó vào HTML.
- Cá nhân hóa, hoặc hiển thị điều hướng duy nhất cho một loại khách truy cập cụ thể so với những người truy cập khác. Việc này chính là đang che giấu trình thu thập công cụ tìm kiếm.
- Không liên kết đến một trang chính trên trang web.
Trang Web không có cấu trúc thông tin rõ ràng #
Cấu trúc thông tin là điều hành và dán nhãn nội dung trên một trang web để cải thiện hiệu quả và khả năng tìm kiếm cho người dùng. Thế nên, kiến trúc thông tin cần phải trực quan, giúp người dùng không mất nhiều thời gian để tìm kiếm một cái gì đó.
Không sử dụng file Sitemap.xml #
Sitemap (Sơ đồ trang web) giống như một danh sách các URL trên trang web của bạn mà trình thu thập thông tin có thể sử dụng để khám phá và lập chỉ mục nội dung của bạn.
Một trong những cách đơn giản nhất để đảm bảo Google tìm thấy các trang ưu tiên cao nhất của bạn là tạo một tệp Sitemap.xml đáp ứng các tiêu chuẩn của Google và gửi nó thông qua Google Search Console. Việc này giúp trình thu thập thông tin theo một đường dẫn đến tất cả các trang quan trọng của bạn.
Lưu ý khi sử dụng file Sitemap.xml #
Khi sử dụng file Sitemap.xml, cần đảm bảo rằng:
- Chỉ bao gồm các URL mà bạn muốn được công cụ tìm kiếm lập chỉ mục.
- Không khai báo URL trong sơ đồ trang web nếu đã chặn URL đó qua tệp Robots.txt.
- Không khai báo các URL trùng lặp.
Ngoài ra, nếu một Website không có bất kỳ trang web nào khác liên kết, bạn vẫn có thể lập chỉ mục cho nó bằng cách gửi file Sitmap.xml trong Google Search Console.
Các trình thu thập thông tin có bị lỗi khi họ cố truy cập URL của bạn không? #
Trong quá trình thu thập dữ liệu URL trên trang web của bạn, trình thu thập thông tin có thể gặp lỗi. Bạn có thể truy cập báo cáo “Crawl Errors” của Google Search Console để phát hiện các URL có thể đang xảy ra. Báo cáo này sẽ hiển thị cho bạn các lỗi máy chủ và không tìm thấy lỗi. Các tệp nhật ký máy chủ cũng có thể cho bạn thấy điều này cùng với thông tin khác như tần số thu thập dữ liệu, nhưng vì việc truy cập và mổ xẻ các tệp nhật ký máy chủ là một chiến thuật nâng cao hơn.
Mã 4xx: Khi trình thu thập công cụ tìm kiếm không thể truy cập nội dung của bạn do lỗi máy khách #
Lỗi 4xx là lỗi máy khách. Nghĩa là URL được yêu cầu chứa cú pháp sai hoặc không thể thực hiện được. Một trong những lỗi 4xx phổ biến nhất là lỗi 404. Những điều này có thể xảy ra do lỗi chính tả URL, trang bị xóa hoặc chuyển hướng bị hỏng.
Khi các công cụ tìm kiếm đạt 404, họ không thể truy cập URL. Khi người dùng đạt 404, họ có thể thất vọng và rời đi.
Mã 5xx: Khi trình thu nhập công cụ tìm kiếm không thể truy cập nội dung của bạn do lỗi máy chủ #
Lỗi 5xx là lỗi máy chủ, nghĩa là máy chủ của trang web bị lỗi không thể đáp ứng yêu cầu của người tìm kiếm hoặc công cụ tìm kiếm để truy cập trang. Trong báo cáo Lỗi thu thập dữ liệu của Google Search Console, có một tab dành riêng cho các lỗi này. Điều này thường xảy ra vì yêu cầu URL đã hết thời gian, vì vậy Googlebot đã từ bỏ yêu cầu.
Hướng giải quyết #
Có một cách để nói với cả người tìm kiếm và công cụ tìm kiếm rằng trang của bạn đã di chuyển – chuyển hướng 301 (vĩnh viễn).
Giả sử bạn chuyển một trang từ: example.com/young-dogs/ sang example.com/puppies/
Công cụ tìm kiếm và người dùng cần một liên kết để chuyển từ URL cũ sang URL mới. Liên kết đó là một chuyển hướng 301.
Mã trạng thái 301 có nghĩa là trang Web đã di chuyển vĩnh viễn đến một vị trí mới. Do đó, tránh chuyển hướng URL đến các trang không liên quan – URL nơi nội dung của URL cũ không thực sự tồn tại. Nếu một trang đang xếp hạng cho một truy vấn và bạn 301 nó đến một URL có nội dung khác. Nó có thể rơi vào vị trí xếp hạng vì nội dung khiến nó liên quan đến truy vấn cụ thể đó không còn nữa.
Ảnh hưởng khi Redirect 301 và không thực hiện Redirect 301 #
| Khi bạn thực hiện 301 | Khi bạn không thực hiện 301 | |
| Link Equity | Chuyển vốn chủ sở hữu liên kết từ vị trí cũ của trang sang URL mới | Nếu không có 301, quyền hạn từ URL trước đó sẽ không được chuyển sang phiên bản mới của URL |
Indexing (lập chỉ mục) | Giúp Google tìm và lập chỉ mục phiên bản mới của trang | Chỉ riêng sự hiện diện của lỗi 404 trên trang web của bạn không gây hại cho hiệu suất tìm kiếm, nhưng để cho xếp hạng/tương tác trang 404 có thể bị loại ra khỏi chỉ mục, với thứ hạng và lưu lượng truy cập đi cùng cùng với thứ hạng và lượng tương tác |
| Kinh nghiệm người dùng | Đảm bảo người dùng tìm thấy trang họ đang tìm kiếm | Cho phép người truy cập nhấp vào liên kết lỗi, sẽ đưa họ đến các trang lỗi thay vì trang dự định. Điều này có thể gây khó chịu |
Bạn cũng có tùy chọn 302 để chuyển hướng một trang. Nhưng điều này nên được dành riêng cho các di chuyển tạm thời và trong trường hợp chuyển giao vốn liên kết không phải là vấn đề đáng lo ngại.
Kết luận #
Trên đây là những thông tin chi tiết về khái niệm Crawling là gì và cách tối ưu quá trình Google thu thập dữ liệu trên Website. Vốn rất quan trọng với những doanh nghiệp cung cấp dịch vụ SEO.
Khi bạn đã đảm bảo trang web của mình được tối ưu hóa cho quá trình Crawling dữ liệu, việc tiếp theo của doanh nghiệp là đảm bảo nó có thể được lập chỉ mục (Indexing). Hãy theo dõi bài viết tiếp theo của NAVEE để cùng tìm hiểu về Indexing nhé!
Được tài trợ






